Welcome! As the title suggests this is about creating a neural network, an adapting AI!
Now I’ve already done most of the research and I think this is possible, I just lack the motivation to work on it. So I’ll post my workings here for you guys to work together and figure this out, I can answer any questions you have but anything in general about AI itself Google it or find a video. Kids these days don’t know what a search bar is. So here’s an explanation about one part of it, Forward Pass.
Taken from my guide I wanted to make on the subject
Neural Networking is a machine version of our human brains. Like our brains, they contain neurons, parts of the code which uses weights and biases to put importance on tasks. These neurons are assigned into layers, called the Input layer, Hidden layer, and Output layer.
Uses
Before I even get into what happens here, what even is the use for neural networks? Like I said, neural networks is a machine version of our brain. This means that we can give the machine values from the game to help it make real time decisions. For example, in a kingdom game where you look after resources such as happiness, money, food, and construction, AI can decide which actions are most important at times where they need to do an action. If we can make advanced AI, it can lead to player vs bot games other than simple sentries. Beside this, AI can learn our personality and use that to stylize the game to our liking. However that form of learning belongs in unsupervised learning, where we are doing supervised.
Beginner Level
-
Input Layer
This is the start of the system, it is where you input information about certain aspects. For example, if you were making an AI to tell dogs and cats apart, you might give ear and tail lengths for the AI to examine. -
Hidden Layer
This is where most of the magic happens. It’s where the math is implemented to calculate a value to be passed on to the next layer. This would be where the AI would grab those tail and ear lengths and make work of it. It would use those input values along with separate weights and biases in each one to make another number. -
Output Layer
Just like it’s name, this is where the output goes. After all the math is done, the AI might output a number between 0 and 1. It then compares it’s two values (one output was under the assumption it’s a dog and the other is done under the assumption it’s a cat). It would then see which number is larger and make it’s prediction. [1]
Mediocre Level
So what math exactly happens here?No math happens in the input layer, so the calculations only begin in the hidden layer. What happens is that each input is multiplied with it’s own weight, and has bias added to it.
weighted_sum = (input_1 * weight_1) + (input_2 * weight_2) + (input_3 * weight_3) + bias
Then after this, we pass it through a sigmoid function which basically condenses the number into a decimal between 0 and 1.
Sigmoid can be thought of as 1/1+e^-x where x is the weighted_sum I wrote in the equation above. This equation doesn’t change, each neuron goes through the same calculation. The only difference is that for future neurons, their input is the sigmoid output from past neurons. An important thing to note is that each neuron starts with a randomized weight and bias that can be between -1 to 1. The reason for this is to allow for learning within the AI, like specialization for more complex actions to help it decide better for it’s course of action.
Now, this is actually it for calculating going forward. The real math will happen for backpropagation, when we have to find our error and update the weights and biases to make the AI smarter in it’s decision making. For now, we can begin with the first part.
If you read that congratulations you now know some of the basics of how this works. Anyways, reason I’m making this topic in the first place anyways is that I had to revise my system at least twice with dramatic changes. So what I’m about to tell you is by far the most memory efficient option at least theoretically.
The Idea
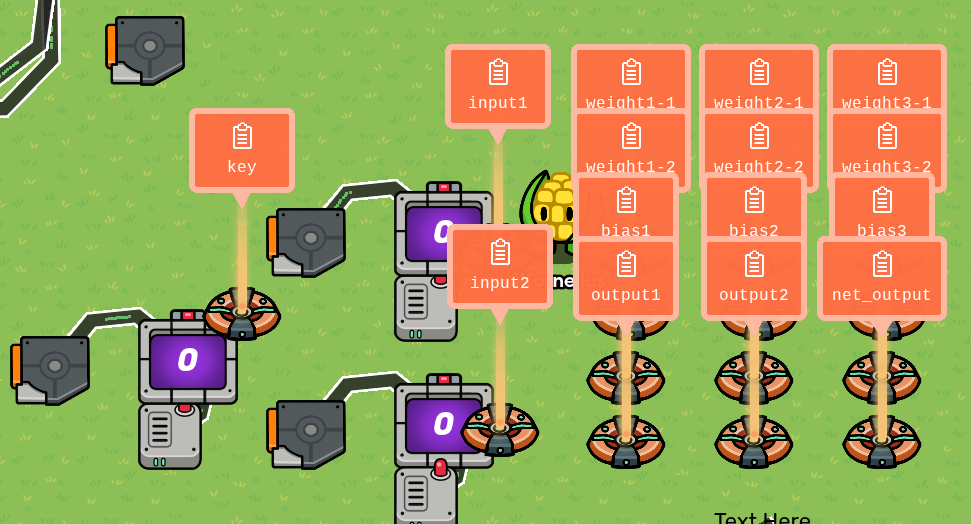
Basically, we want to do the most intense amount of concatenation known to Gimkit kind. The idea is to make what I’d like to call “Hubs” to store all the information for us to withdraw. If you read my explanation above you know what the “Inputs” and “Weights” are. I was thinking of making properties that hold certain number of weights per input and they are separated by certain characters like &[insert weights here]& or something like that so the AI can withdraw them for its calculations. If that sounds confusing, good that’s why I decided to post this. This isn’t for everyone so if you don’t think you can offer anything of use don’t reply and only post something meaningful. Anyways, as one who is bored of this place I won’t be the one to actively work on code unless summoned [2].
That’s most of it, anyone with a question about backpropagation, which if you’re curious I can explain at a later time, just Google it.
Uh, good luck.
By the way, I had some notes written but they’re on a different computer I can’t access right now, so give me a couple more hours and you’ll get some more information on the topic. If you flag this I don’t care just wondering if anyone was curious on this.
Great news got access to some more info so here’s a notepad of my inner thoughts:
gotta figure out the neural network
so concatenation is a big yes if we want this thing to not be memory intensive and actually hold a good deal of information without using too many properties or memory.
Now we need weights all in one property, mind this, weights are for each neuron based on how many inputs it’s receiving. This could be more or less depending on specialization, but I feel this might mess with the system.
I also need to make sure i use only one trigger at least because if we concatenate we can just repeat until all the neurons have calculated.
We also have to condense all the names of neurons into a property. Technically these would never actually exist but would only exist in theory, based on matching which index matches which. For example, character 5 would be the 5th neuron and has these 3 neurons.
If we imagine we have 6 neurons, 2 inputs, 2 hidden, and 2 outputs, then both inputs would go into both hidden but come out as two different numbers since both hidden neurons have different weights and biases. This happens with the output again.
i believe the biggest problem is grabbing the numbers and then changing them again with backpropagation.
Let’s do an example. same example as before.
input 1 = .1 (I might shorten this by saying I for input)
input 2 = .4
Remember they don’t have weights, they just pass their values on.
hidden1weight1 = .2 (might simplify by saying H1W1 where h is hidden and w is weight. This will save space in character limit)
hidden1weight2 = .5
hidden2weight1 = .4 (also considering the fact we’re giving numbers to which neuron and which weight might make it easier to find needed values)
hidden2weight2 = .9
so then we would multiply each each input with each weight, so .1 * .2. I’m not including bias right now since if i solve weight i can incorporate the same system for bias.
anyways then we would get a value, .02. This would be the next input for the output value but you get the point now.
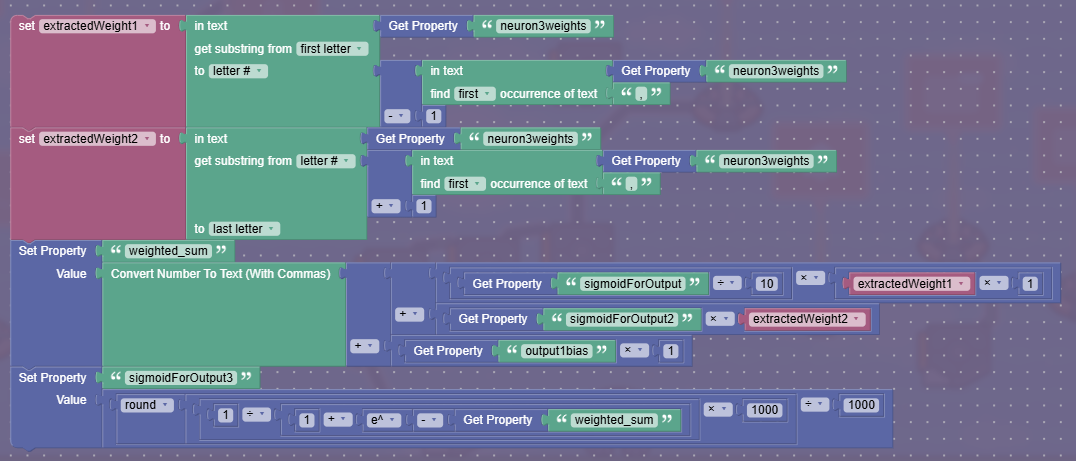
How do we grab the weights though? It’ll be easy enough to grab the neurons, since I’ll label them with numbers I can then use another property for incrementation to see which neuron I’m on. Then some system that after I reach max weights another property resets to 0 and then goes back to counting. since i have 2 weights, we’d go like 1,2 and then reset back to one again when we reach the next neuron. Usually they run in parralel, but I’m not really sure how to do that, and as long as i don’t calculate like a snake but send it to the next layer (which i might add in the neurons’ name to identify like L1H1W1 where L is which layer we’re on, again using a property to keep track)
Apparently i have to save the inputs, so maybe I’d have a different property that keeps track which input belongs to which neuron. Good thing i don’t need it to remember where it goes, so for each input created, I’ll probably save it’s value and place it next to it’s neuron.
following the example again, I’d have them grouped in stages of two, since each neuron has two weights. It does make me wonder though, if i should also place them next to the neuron name, since then I could just find the value. but im not sure, like, how would i separate them? I don’t think I can find the 5th comma, or at least there isn’t a block for that. i could try combining blocks but i doubt id get any good results.
so maybe adding L1H1W1 next to the weights could work. I could force it to grab a certain number of characters ahead of it and then grab that section and place it into a seperate property. Then I could go through it without having to meddle with the other weights. this could work since i would only have to find L[value of Layer]H[value of hidden neuron]W[value of weight]. When i mean value i mean which number or version(?) we’re on. Like 3rd layer 16th neuron with it’s 4th weight.
Now, getting the neuron to figure out what input it needs. I did mention earlier about saving each input created and keeping it next to its creator neuron. So I could subtract 1 in the Layer property and possible iterate through the neurons there. BUT WAIT. how would i figure out when to add another 1 for layers? neurons and weights are easy since they have to added each time, weights added multiply times, so i could do a repeat in a repeat. And then neuron + 1 when i finish the code. But layers go up by 1 at different times. The last layer could have 68628 neurons but the next only 63. Hmm, I could do another property and label or highlight which neurons are the last in a layer, so when the code finishes, it just adds 1 since it knows in the property it will go to the next layer. I’m thinking of also placing the first number in the layer, probably spaced with a ! before or after it so it’ll be different. This might make it easier to iterate through the previous layer since it can just grab the first and last neuron and reiterate through there, at least just for the inputs.
Or perhaps(!) i can just make a property to hold all the inputs created so when we run it’ll grab through those inputs and then replace them with the newly created ones for the next layer. Obviously i’ll still save them with their creator neuron since i still need them for backpropagation.
Furthering on the finding previous layer thing, maybe if i section them in brackets and close them each closed bracket represents a layer? Maybe they could start as but once i iterate i change them to () to signal they’ve already been used and whatnot.
****** Make sure to read future Me.
Ok, quick recap. As of right now I have decided to give specific names to the Neurons, like L1H1W1, or many just L1N1W1 where L is layer (this will be important during not only backpropagation but the forward pass too when future layers need to grab their respective inputs from previous ones). Since all of the properties are gonna be named “Neuron”, there won’t be any distinction between which is hidden or which is output. This is why i suggest we have an if detecting if a neuron has a number that makes it an output. For example, say we have 6 neurons as before, the last two (5 and 6) are the outputs, so we’d check if the neuron we’re on is 5 or above, if so it’s an output and its value should be saved for final consideration.
Here’s what I’m thinking for weights and neurons. Earlier above i mentioned condensing them in one property but didn’t give much thought. The weights should be grouped in a way i know where one neuron weight starts and another one ends. Once again maybe using brackets or curved brackets to group them together. Perhaps with the Neuron they identify with also.
Ex: N1(.1, -.3, .8)N2(.2, .6, -.4)…
But with the negatives it’s an extra letter, so what do i do about it. Extra